RISC-V:跟着清华训练营从零打造OS【第二课】
上一节回顾
在RISC-V:跟着清华训练营从零打造OS【第一课】中,我们学习了三叶虫LibOS总体结构以及相关环境的配置,本节课将主要探讨批处理系统的设计以及多道程序与分时任务设计,这两章节内容颇具启发性和趣味性,相信会引发大家的浓厚兴趣。
批处理系统设计
上一节课在 RISC-V 64 裸机平台上成功运行 Hello, world!。看起来这个过程非常顺利,只需要一条命令就能全部完成。架构也比较简单,通过Qemu加载App和LibOS镜像到内存中,由RustSBI完成硬件初始化后,跳转到OS起始位置,执行App相关逻辑。但实际上,在那个计算机刚刚诞生的年代,很多事情并不像我们想象的那么简单。

本节课的批处理系统(名为:邓氏鱼BatchOS操作系统)总体架构如图所示:
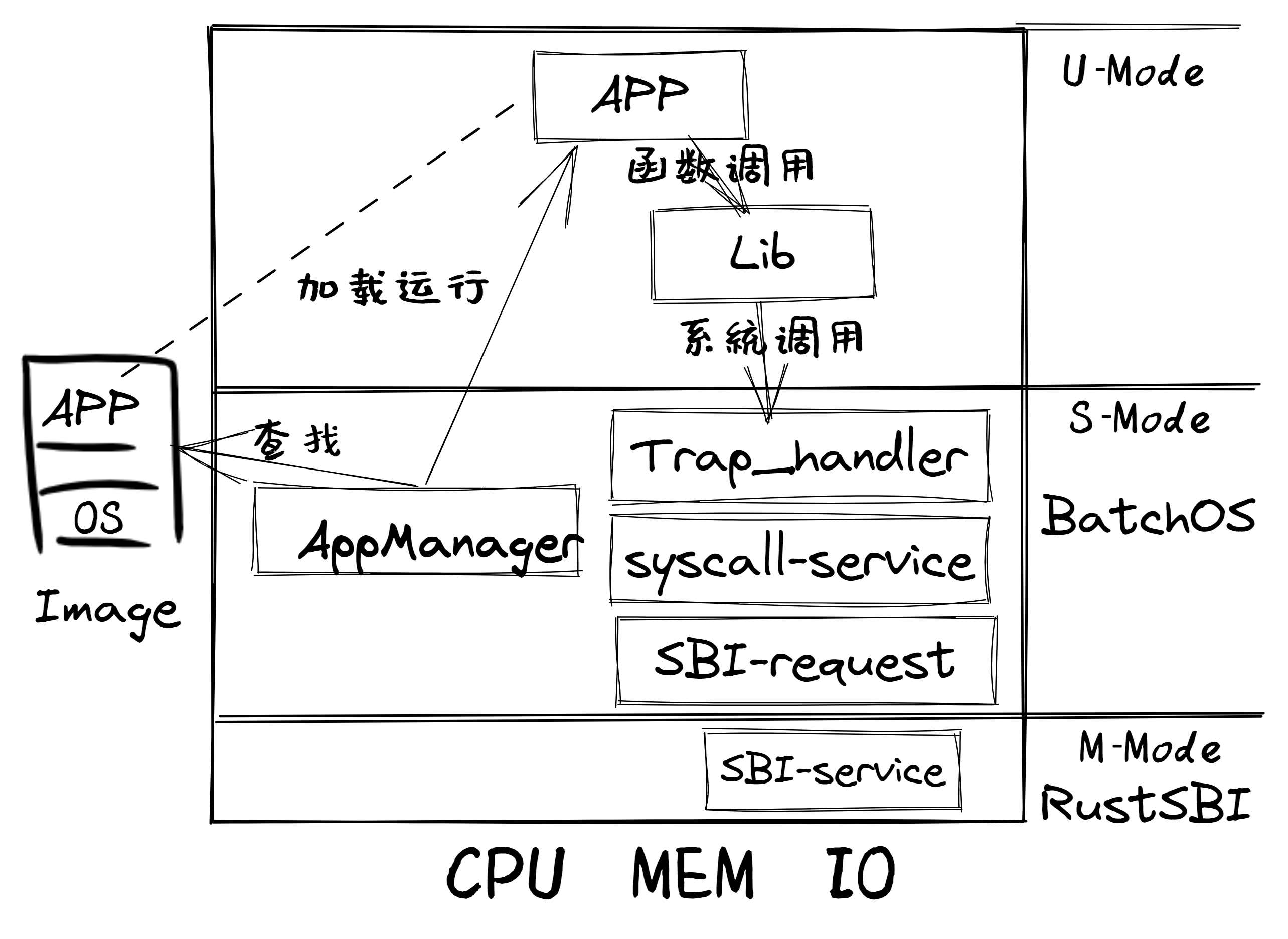
通过上图,我们可以大致了解到,Qemu 将包含多个 app 的列表以及 BatchOS 的 image 镜像加载到内存中。
- 在
RustSBI(bootloader)完成基本硬件初始化后,跳转到BatchOS的起始位置。 - 进行正常运行前的初始化工作,包括建立栈空间和清零
bss段。 - 通过
AppManager内核模块从app 列表中依次加载各app到指定内存中,并在用户态执行。 - 在
app执行过程中,可通过系统调用的方式获得BatchOS提供的 OS 服务,如输出字符串等。
批处理系统将多个程序打包一起输入计算机并逐个执行,但由于应用程序可能存在错误,如果某个程序的错误导致整个操作系统无法运行,后果将不堪设想。
为了保护操作系统免受错误程序的破坏,特权级(Privilege)机制应运而生,它实现了用户态和内核态的隔离。在RISC-V 架构中,一共定义了 4 种特权级:
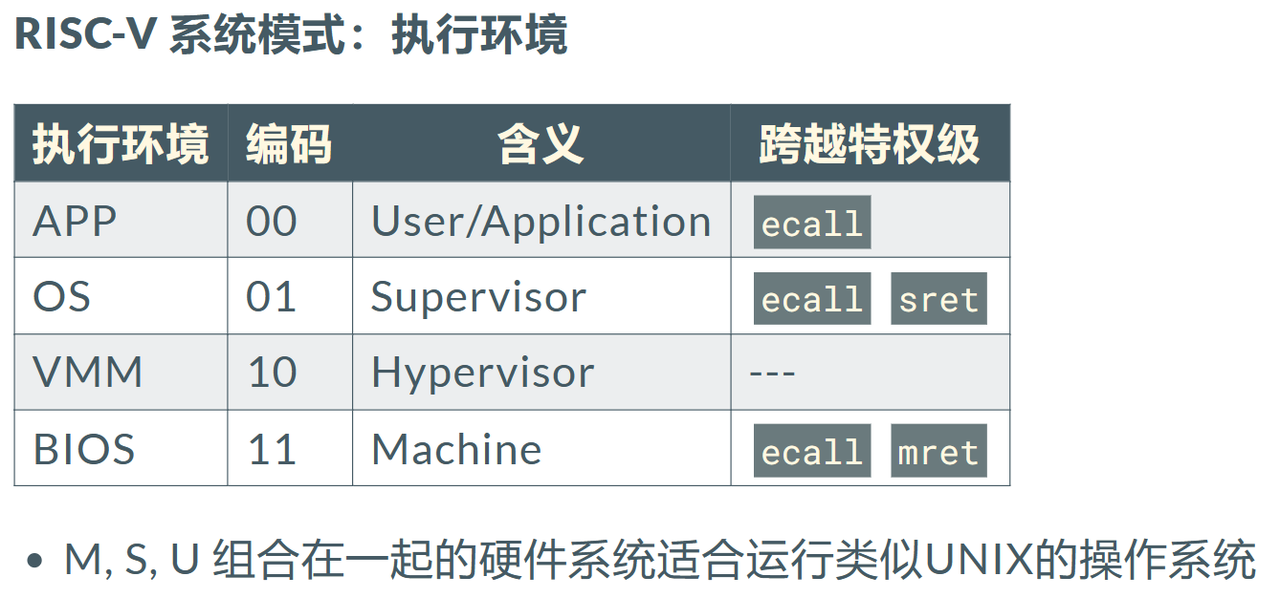
其中,级别的数值越大,特权级越高,掌控硬件的能力越强。从表中可以看出, M 模式处在最高的特权级,而 U 模式处于最低的特权级。在CPU硬件层面,除了M模式必须存在外,其它模式可以不存在。
接下来,让我们一起来回顾一下这两课的架构概述。在最右侧的图中,我们引入了一个名为 Hypervisor 的抽象层,用以服务于多个操作系统。
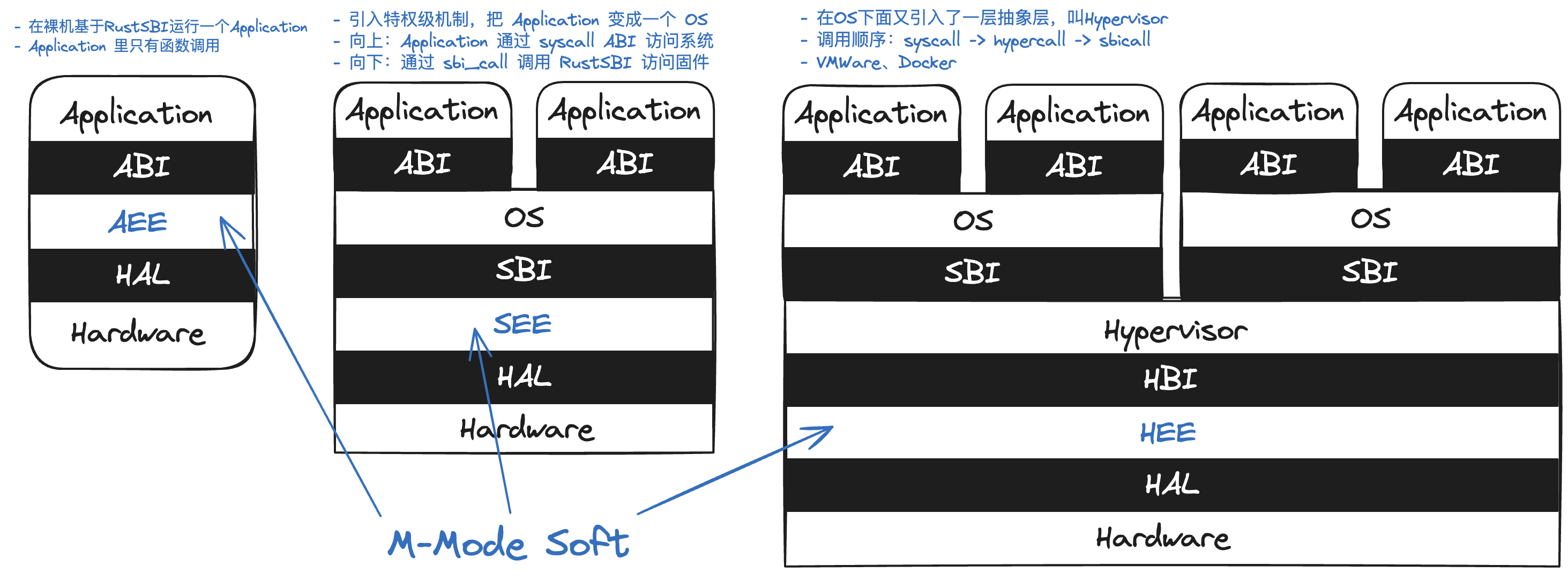
通过 link_app.S 代码将应用程序链接到内核,接着,应用管理器 AppManager 加载应用程序二进制代码。在此过程中,强调了屏障指令 fence.i 的重要性。由于 CPU 对物理内存的缓存分为数据缓存(d-cache)和指令缓存(i-cache)两部分,在 CPU 访问内存和提取指令时分别使用。而 fence.i 的功能是确保其在后的取指过程能看到其在前的所有对取指内存区域的修改。
最后,由于处理器具有硬件级特权级机制,应用程序在用户态特权级运行时,无法直接通过函数调用访问内核态特权级的批处理操作系统内核函数。然而,应用程序需要获得操作系统提供的服务,因此应用程序与操作系统需要通过某种合作机制完成特权级之间的切换,使得用户态应用程序可以获得内核态操作系统函数的服务。
多道程序与分时多任务
批处理与多道程序的主要区别在于内存使用和处理器调度策略。
批处理系统中,一段时间内可以处理一批程序,但内存中仅存放一个程序。处理器一次只能运行一个程序。当一个程序运行完毕后,才会将另一个程序调入内存并执行。换句话说,批处理系统无法交错地执行多个程序。
而在支持多道程序的系统中,一段时间内也可处理一批程序,但内存中可以存放多个程序。在执行过程中,一个程序可以主动(协作式)或被动(抢占式)地放弃执行,让另一个程序得以执行。这意味着支持多道程序的系统能够交错地执行多个程序,从而提高系统利用率。
总之,批处理系统和多道程序系统在内存管理和处理器调度策略上有显著差别,导致它们在执行多个程序时的效率不同。
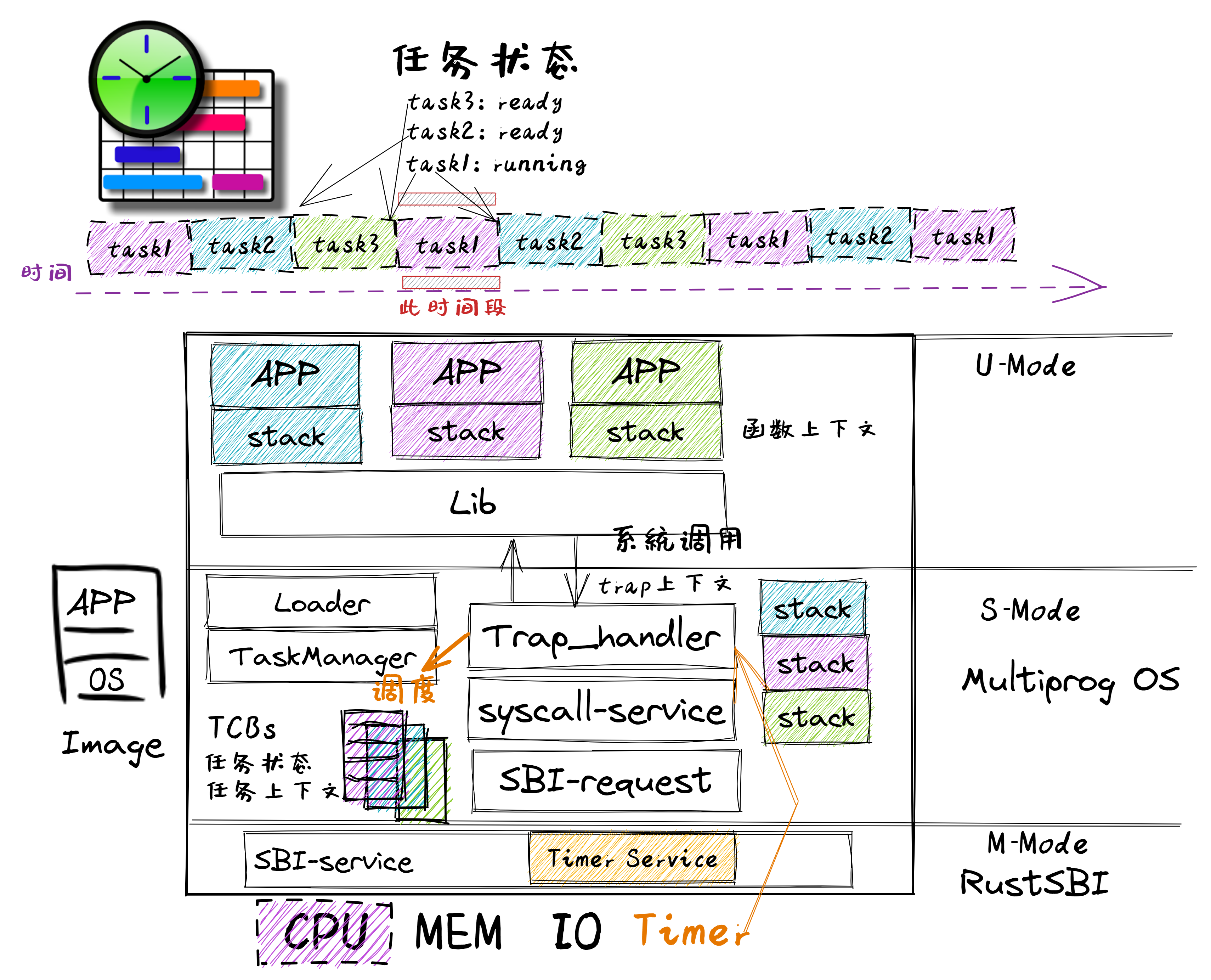
站在系统的层面,还是需要有一种办法能强制打断应用程序的执行,来提高整个系统的效率,让在整个系统中执行的多个程序之间占用计算机资源的情况相对公平一些。
根据计算机系统的硬件设计,为提高 I/O 效率,外设可以通过硬件中断机制来与处理机进行 I/O 交互操作。这种硬件中断机制可随时打断应用程序的执行,并让操作系统来完成对外设的 I/O 响应。
最后,让我们以一段关于「中断」的有趣、生动且形象的解释来总结本节所学到的关键内容。这段解释来源于老师在训练营群里分享的聊天记录:
1 | 这不就是中断模式下的CPU处理方式么? |
未完待续 … …
以上就是关于 [清华开源操作系统训练营] 第二课学到的知识,希望对您有所帮助。祝大家玩得开心 ^_^
如果您喜欢这篇文章,欢迎关注微信公众号《猿禹宙》、点赞、转发和赞赏。每一位读者的认可都是我持续创作的动力。
